








KAIST, 적은 데이터로 정밀 동작 학습하는 로봇 AI 개발
디스포(DiSPo)는 사람이 띄엄띄엄 보여준 적은 동작 데이터만으로 학습하고도, 작업 상황에 맞춰 움직임의 정밀도를 스스로 조절해 정교한 동작을 만들어내는 로봇 인공지능 모델이다.
KAIST(총장 이광형)는 전산학부 박대형 교수 연구팀이 사용자가 원하는 정밀도에 맞춰 움직임을 세밀하게 생성하는 다중 정밀도 조작 모델 디스포를 개발했다고 24일 밝혔다. 기존 로봇 AI가 정밀한 작업을 배우려면 짧은 시간 간격으로 촘촘히 기록한 방대한 데이터가 필요했던 것과 달리, 디스포는 데이터 수집 부담을 크게 줄이면서도 좁은 틈에 부품을 끼우고 작은 버튼을 누르는 초정밀 작업을 해낸다. 연구팀은 시뮬레이션에서 기존 최고 성능 모델보다 작업 성공률을 최대 81% 끌어올렸다고 밝혔다.
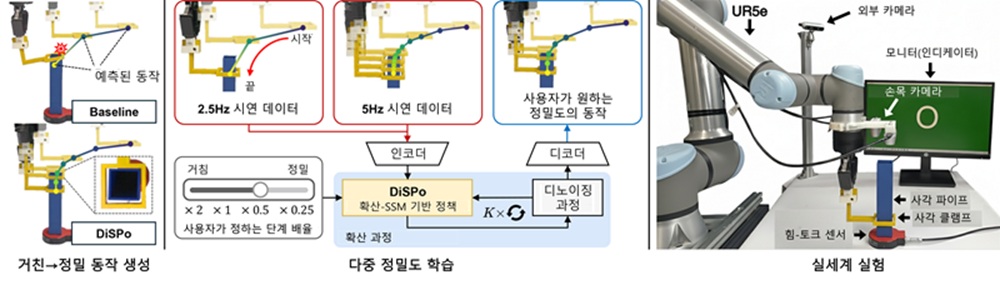
정밀 동작 학습의 데이터 장벽…’맘바’와 확산모델의 결합으로 넘다
로봇에게 정밀한 손작업을 가르치는 일은 오랫동안 데이터 비용의 문제였다. 기존 로봇 인공지능은 사람이 움직이는 모습을 매우 짧은 시간 간격으로 촘촘히 기록한 방대한 데이터를 학습해야 정밀한 작업을 수행할 수 있었다. 나사를 조이거나 좁은 틈에 부품을 끼워 넣는 동작 하나를 배우려면 수많은 동작 데이터를 세밀하게 수집해야 했고, 그만큼 시간과 비용이 많이 들었다. 단위 시간에 동작 정보를 촘촘하게 담은 데이터를 고주파 시연(짧은 간격으로 빽빽하게 수집한 시범), 듬성하게 담은 데이터를 저주파 시연이라 부른다.
더 근본적인 한계는 기존 학습 모델이 학습에 쓴 데이터의 시간 간격에 그대로 묶인다는 점이었다. 짧은 간격의 고주파 데이터로 배운 모델은 그 정밀도에서 벗어나기 어렵고, 간격이 느슨한 저주파 데이터로는 애초에 정밀한 동작을 만들어내기 힘들었다. 정밀한 작업을 가르치려면 매번 방대한 고주파 데이터를 새로 모아야 하는 구조였던 셈이다.
연구팀은 이 한계를 두 가지 인공지능 모델을 결합해 풀었다. 하나는 시간에 따른 변화를 효율적으로 학습하는 상태공간 모델(SSM, 시계열 데이터를 빠르고 메모리 효율적으로 처리하는 신경망 구조)의 최신 형태인 ‘맘바(Mamba)’로, 입력 신호로부터 동작을 끊어 읽는 시간 간격을 스스로 예측한다. 다른 하나는 무작위 노이즈에서 출발해 잡음을 점차 걷어내며 다양한 동작을 만들어내는 확산모델(Diffusion Model)이다. 연구팀은 여기에 ‘단계 조정 계수(step-scale factor)’라는 장치를 새로 더했다. 맘바가 예측한 시간 간격에 사용자의 의도가 담긴 계수를 곱해, 모델이 동작을 얼마나 잘게 나눠 처리할지를 바깥에서 직접 조절할 수 있게 한 것이다.
이 구조 덕분에 로봇은 느슨하게 시범을 본 뒤에도 필요할 때 스스로 동작을 더 잘게 쪼개 정교하게 움직일 수 있다. 연구팀은 한발 더 나아가, 적은 데이터로 1차 학습한 모델이 저주파 시연으로부터 더 촘촘한 의사 시연(pseudo demonstration, 모델이 스스로 만들어낸 가상의 정밀 연습 데이터)을 만들어내고, 이를 원래 데이터와 함께 다시 학습에 쓰도록 했다. 사람이 정밀한 시범을 일일이 더 보여주지 않아도, 로봇이 부족한 데이터를 스스로 채워가며 원본에는 없던 정밀한 동작 패턴까지 익히는 셈이다. 박대형 교수는 “이번 연구는 로봇이 적은 양의 데이터만으로도 정교한 동작을 학습하고 작업 상황에 따라 스스로 정밀도를 조절할 수 있음을 보여준 사례”라고 설명했다.

2.5mm 틈 통과와 셔터 누르기로 입증…제조·의료 자동화로 확장
디스포의 성능은 가상 환경 실험과 실제 로봇 실험에서 모두 확인됐다. 시뮬레이션 환경에서 디스포는 기존 최고 성능 모델 대비 작업 성공률을 최대 81% 높였다. 사람이 큰 동작과 정밀한 동작을 작업 상황에 따라 자유롭게 오가듯, 서로 다른 시간 해상도의 동작을 하나의 모델로 통합해 다루는 다중 정밀도(multi-granularity, 큰 이동 동작부터 미세한 조작까지 통합적으로 다루는 능력) 능력을 갖춘 결과다.
실제 협동로봇을 이용한 실험에서는 반경 2.5mm에 불과한 좁은 틈에 부품을 끼워 넣고, 스마트폰의 작은 셔터 버튼을 정확히 누르는 고난도 작업을 안정적으로 수행했다. 연구팀은 이를 기존 인공지능 모델보다 최대 4배 높은 성공률이라고 밝혔다. 시뮬레이션에서 잘 작동하던 모델을 실제 로봇으로 옮겨 이런 초정밀 작업을 안정적으로 해내기까지가 연구에서 가장 까다로운 과정이었다.
연구팀은 이 기술이 정밀 부품 조립, 케이블 연결, 의료 수술, 정밀 가공처럼 높은 정확성이 요구되는 다양한 산업 분야에 적용될 수 있을 것으로 기대했다. 적은 데이터만으로도 고정밀 로봇을 학습시킬 수 있다는 점이 핵심이다. 이를 통해 로봇 개발 비용을 크게 낮추고, 제조·의료·서비스 산업의 자동화를 앞당기는 데 기여할 것이라는 게 연구팀의 설명이다.
적은 데이터로 정밀도를 확보한다는 점은 현장의 작업 방식을 바꿀 수 있다. 작업자가 동작을 한 번 대충 보여주는 것만으로 로봇이 정밀한 조립을 익히거나, 같은 로봇이 작업 구간에 따라 거친 동작과 정밀한 동작을 스스로 오가는 식이다. 박대형 교수는 “앞으로 데이터 수집 비용을 획기적으로 줄이면서도 정밀 제조와 의료 등 다양한 산업 현장에서 활용할 수 있는 범용 로봇 학습 기술로 발전시켜 나가겠다”고 말했다.








