








UNIST, 음성 속 감정 읽어 영상 속 화자 표정 바꾸는 AI 개발
“잘한다” 같은 말은 어조에 따라 칭찬이 될 수도 있고 비꼬는 말이 될 수도 있다. 같은 말에 담긴 이 미묘한 감정의 결을 읽어, 영상 속 인물의 표정까지 그에 맞게 바꾸는 기술이 나왔다.
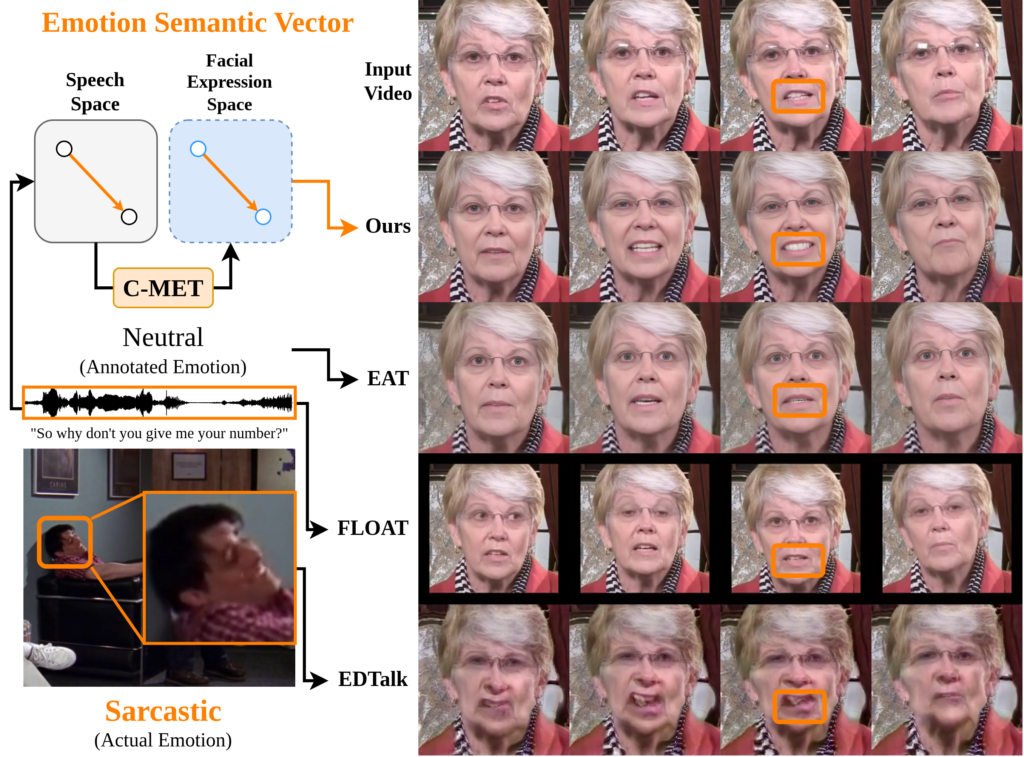
음성에 담긴 감정을 읽어내 영상 속 화자의 얼굴 표정을 원하는 감정으로 바꿔 주는 AI 기술이 나왔다. UNIST(울산과학기술원) 인공지능대학원 김태환 교수팀은 음성 신호에서 감정을 추출해, 별도의 참조 이미지 없이도 영상 속 화자의 표정을 원하는 감정으로 바꿀 수 있는 인공지능 모듈 ‘C-MET(Cross-Modal Emotion Transfer)’을 개발했다고 18일 밝혔다.
기존 기술이 감정별 고품질 사진을 필요로 하거나 정해진 감정 목록 안에서만 표정을 만들 수 있었던 것과 달리, C-MET은 음성만으로 학습 과정에서 보지 못한 미묘한 감정까지 표현한다. 감정 표현 정확도도 최신 기술보다 약 14%p(퍼센트포인트) 높았다. 이번 연구는 인공지능·컴퓨터 비전 분야 국제학회 CVPR 2026에 채택됐다.
참조 사진도, 감정 이름표도 필요했던 기존 방식
말하는 얼굴 합성(talking face generation, 음성을 입력받아 사람 얼굴이 말하는 영상을 자동으로 생성하는 기술)은 가상 인간, 디지털 아바타, 영상 콘텐츠 제작 등에 쓰인다. 이때 표현력을 높이려면 원하는 감정을 얼굴에 자연스럽게 담는 감정 편집(emotion editing, 얼굴 영상에서 정체성·입 모양은 그대로 둔 채 표정의 감정만 바꾸는 기술)이 중요하다.
하지만 기존 방식에는 저마다 한계가 있었다. 감정에 ‘기쁨’·’슬픔’ 같은 이름표를 붙여 학습시키는 방식은 미리 정해 둔 감정 범주 안에서만 표현이 가능했다. 음성을 활용하는 방식은 음성 안에 말의 내용과 감정이 뒤섞여 있어 감정만 따로 떼어 내기 어려웠다. 또 원하는 감정을 보여주는 얼굴 사진, 즉 참조 이미지(reference image)를 넣어 표정을 따라 하게 하는 방식은 감정마다 고품질 사진을 따로 준비해야 했다.
특히 비꼬는 표정처럼 학습 데이터에 들어 있지 않은 미묘한 감정은 기존 방법으로 표현하기가 사실상 불가능했다. 정해진 목록에 없거나 사진으로 담기 어려운 복합적인 감정은 다룰 수 없었던 셈이다. C-MET은 바로 이 지점을 겨냥했다.
감정의 ‘변화량’을 표정의 ‘변화량’으로 옮긴다
C-MET의 핵심 아이디어는 감정의 ‘변화량’을 다룬다는 데 있다. 감정 자체에 이름표를 붙이는 대신, 중립적인 음성과 감정이 실린 음성의 차이를 벡터(vector, 변화의 방향과 크기를 담은 숫자 정보)로 계산한다. 같은 방식으로 얼굴에서도 중립 표정과 감정 표정의 차이를 벡터로 나타낸 뒤, 음성의 감정 변화 벡터가 얼굴의 표정 변화 벡터로 어떻게 이어지는지를 AI가 학습한다. 음성과 영상이라는 서로 다른 형태의 정보를 잇는 교차 모달(cross-modal) 방식이다.
이 덕분에 음성 안에 말의 내용과 감정이 함께 섞여 있어도, 표정 변화에 필요한 감정 신호만 따로 읽어낼 수 있다. 같은 문장이라도 어조가 달라지면 입꼬리, 눈썹, 눈 주변 움직임이 다르게 나타나도록 표정을 바꾼다. 원래 화자의 얼굴 특징과 입 모양, 고개 움직임은 그대로 두고 표정만 원하는 감정으로 교체하는 것이다.
두 감정 사이의 변화량을 보는 방식이기에, 정해진 감정 목록에 얽매이지 않는다. 비꼼, 공감, 카리스마처럼 학습 과정에서 직접 보지 못한 미묘한 감정도 얼굴 표정에 반영할 수 있다. 또 입력으로 감정이 담긴 음성을 쓰기 때문에, 감정을 표현한 고품질 정면 사진 같은 참조 이미지도 필요하지 않다.
14%p 높은 정확도에 ‘끼워 쓰는’ 범용성까지
성능 면에서 C-MET은 최신 기술을 앞섰다. 최신 말하는 얼굴 표정 편집 기술인 ‘이디톡(EDTalk)’과 비교해 감정 표현 정확도가 14%p 이상 높았다. 기존 EDTalk 모델의 표정 인코더를 C-MET으로 대체해 실험한 결과, 감정 음성·영상 데이터셋인 MEAD 기준 감정 정확도가 41.99%에서 55.91%로 향상됐다.
주목할 점은 C-MET이 특정 모델에만 묶이지 않는 모듈형이라는 것이다. 부품처럼 기존 모델에 끼워 쓸 수 있어, 또 다른 말하는 얼굴 생성 모델인 ‘PD-FGC’에 적용했을 때도 감정 정확도가 33.36%에서 36.82%로 높아졌다. 두 모델 모두에서 추론(inference, 학습한 AI가 새 입력을 받아 결과를 내놓는 단계) 속도도 빨라졌다. 특정 모델 전용이 아니라 여러 얼굴 생성 AI에 두루 적용될 수 있음을 보여주는 결과다.
김태환 교수는 “이번 연구는 참조 이미지 없이 음성만으로 얼굴 영상의 감정을 바꿀 수 있다는 점에서 기존 방식들의 한계를 실질적으로 해결했다”며 “가상 인간 제작, 영화·콘텐츠 후반 작업, 감정 인식 AI 등 다양한 분야에 폭넓게 활용될 수 있는 기반 기술”이라고 설명했다.








