UNIST, ‘보고 듣는 AI’가 더 안정적인 이유 수학으로 규명…흔들림 없는 AI 설계 토대
이미지와 음성, 텍스트를 한꺼번에 학습하는 ‘멀티모달 인공지능(AI)’이 한 종류의 데이터만 배운 AI보다 더 정확하고 외부 변화에 잘 흔들리지 않는 이유가 수학적으로 규명됐다.
UNIST 인공지능대학원 윤성환 교수팀은 멀티모달 AI가 단일모달 AI보다 좋은 성능을 내는 원리를, AI의 학습 오차를 지형처럼 나타낸 ‘손실 지형(loss landscape)’이 더 평탄해지기 때문임을 이론적으로 입증했다고 28일 밝혔다. 멀티모달 AI는 자율주행과 의료, 로봇, 파운데이션 모델 등에 이미 폭넓게 쓰이지만, 정작 ‘왜 더 잘 작동하는가’를 딥러닝 학습 과정과 연결해 설명하는 이론적 근거는 부족했다. 이번 연구는 그 빈틈을 이론으로 메우는 동시에, 같은 원리를 거꾸로 활용해 성능을 한 단계 더 끌어올리는 새 학습법까지 제시했다는 점에서 주목된다.
한 종류만 보던 AI, 여러 감각으로 배우자 더 단단해졌다
멀티모달 학습(multimodal learning)은 이미지와 음성, 텍스트, 영상처럼 형태가 다른 데이터를 함께 활용해 AI를 학습시키는 방법이다. 사람이 사물을 눈으로 보는 동시에 이름을 들으면 더 확실히 기억하듯, 서로 다른 종류의 정보가 부족한 부분을 메워 주기 때문에 한 가지 데이터만 쓰는 모델보다 풍부하고 정확한 표현을 익힐 수 있다. 멀티모달 AI는 이미 자율주행, 의료, 로봇, 그리고 여러 데이터를 폭넓게 다루는 파운데이션 모델(대규모 기반 AI 모델) 등에서 단일모달 AI보다 뛰어난 성능을 내는 것으로 알려져 있다.
문제는 ‘왜’ 더 나은지였다. 그동안 멀티모달 학습의 우수성은 주로 실험 결과로 확인됐을 뿐, 여러 데이터를 함께 학습할 때 일반화 성능과 강건성(robustness)이 좋아지는 근본 원리를 실제 딥러닝 학습 과정과 연결해 설명하는 이론은 충분치 않았다. 여기서 강건성이란 학습 때 보지 못한 새로운 상황이 닥쳐도 성능이 크게 무너지지 않고 버티는 능력을 뜻한다.
윤성환 교수팀은 이 질문의 답을 손실 지형(loss landscape)에서 찾았다. 손실 지형은 AI가 학습 과정에서 내는 오차가 모델 내부의 수많은 설정값(파라미터)에 따라 어떻게 달라지는지를 산과 골짜기가 있는 지형처럼 그려 낸 개념이다. 이 지형이 날카롭고 뾰족하면 작은 변화에도 성능이 크게 흔들리지만, 넓고 완만하면 처음 보는 데이터나 잡음이 들어와도 성능을 안정적으로 유지하기 쉽다. 연구팀은 여러 모달리티를 함께 학습할수록 바로 이 손실 지형이 더 평탄해진다는 사실을 확인했다.
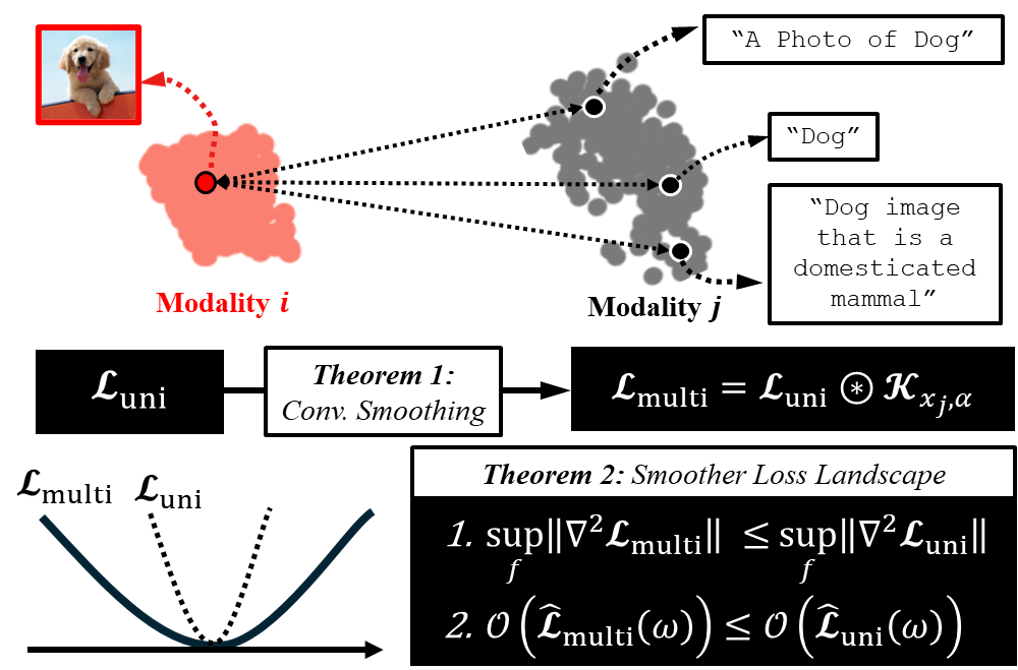
뾰족한 오차를 눌러 펴는 ‘합성곱 스무딩 효과’
연구팀은 손실 지형이 평탄해지는 까닭을 ‘합성곱 스무딩 효과(convolutional smoothing effect)’로 설명했다. 합성곱 스무딩이란 하나의 함수에 다른 데이터 분포를 겹쳐(합성곱) 급격한 변화나 불규칙한 잡음을 완만하게 다듬는 수학적 현상이다. 이미지 하나만 보고 학습할 때 생기는 뾰족한 오차의 변화가, 같은 대상을 가리키는 음성이나 문장 정보와 함께 학습되면서 평균을 내듯 눌리고 퍼지는 것이다.
이를 수식으로 따져 보면, 멀티모달 학습의 손실 함수는 단일 모달리티의 손실 함수에 다른 모달리티의 데이터 분포를 합성곱한 형태로 표현된다는 것이 연구팀의 증명이다. 연구팀은 나아가 멀티모달 손실 지형의 최대 곡률(가장 가파른 정도)이 단일 모달리티보다 커지지 않고, 주파수 관점에서도 불규칙한 고주파 성분이 줄어든다는 점을 보였다. 곡률이 작고 고주파가 적다는 것은 곧 지형이 더 매끄럽고 완만하다는 의미다.
핵심은 이런 평탄화가 별도의 기법 없이 저절로 일어난다는 점이다. 보통은 손실 지형을 일부러 평탄하게 다듬는 별도의 기법을 동원하지만, 멀티모달 학습은 서로 다른 데이터를 함께 쓰는 것만으로 모델을 자연스럽게 완만하고 안정적인 지형으로 이끈다. 연구팀은 이를 두고 멀티모달 AI의 강점이 단순히 ‘더 많은 정보를 쓰기 때문’이 아니라, 서로 다른 모달리티가 학습 과정에서 손실 지형을 부드럽게 만들기 때문이라는 새로운 이론적 근거를 제시했다고 설명했다.
짝을 새로 짜는 학습법 ‘DML’…현장 적용까지 겨냥
연구팀은 이 원리를 거꾸로 활용해 성능을 더 끌어올리는 새 학습법 ‘분포 기반 멀티모달 학습(DML, Distributional Multimodal Learning)’도 함께 내놨다. 기존 방식은 이미지 한 장과 거기에 정확히 대응하는 문장(또는 음성) 하나를 고정된 짝으로 묶어 학습한다. 반면 DML은 같은 정답을 공유하는 데이터끼리라면 원래의 짝이 아니어도 이미지와 문장을 확률적으로 다시 조합한다. 예컨대 ‘고양이’라는 같은 정답을 가진 여러 사진과 설명문을 서로 자유롭게 짝지어 학습에 쓰는 식이다. 이렇게 하면 학습 데이터의 조합이 훨씬 다양해지면서 손실 지형 평탄화 효과가 극대화된다.
성능 검증 결과도 이론을 뒷받침했다. 네 가지 멀티모달 데이터셋에서 실험한 결과, DML은 정해진 짝만 학습하는 기존 방식보다 분류 정확도를 일관되게 높였다. 사진을 보고 알맞은 설명문을 찾거나 설명문을 읽고 알맞은 사진을 찾는 이미지–텍스트 검색에서도 더 많은 정답을 맞혔으며, 손실 지형 분석에서도 기존보다 더 평탄하고 외부 변화에 안정적인 특성을 보였다. DML은 새로운 모델 구조나 복잡한 추가 연산 없이 데이터를 짝짓는 방식만 바꿔 적용할 수 있다는 점에서 실제 활용 가능성이 높다.
연구팀은 “이번 연구는 멀티모달 AI가 왜 더 강건하게 일반화될 수 있는지에 대한 이론적 근거와, 그 근거를 활용한 단순하지만 효율적인 새로운 멀티모달 학습 방법을 제시했다”며 “외부 노이즈나 교란에도 흔들림 없이 안정적으로 작동하는 강건한 AI를 설계하는 중요한 기반 기술이 될 것”이라고 밝혔다. 연구팀은 DML이 이미지–텍스트 파운데이션 모델과 음성·영상 인식, 의료 데이터 분석, 자율주행·로봇처럼 안정성과 일반화 성능이 중요한 분야에 두루 쓰일 것으로 기대했다.